- 文字サイズ
- 小
- 中
- 大
求められる新たな視点と戦略立案
2018年07月26日
加速度的な進化がもたらす「驚きの技術」から、様々な現場に組み込まれる「社会実装の本格化」へ。第三次ブームの最中にある人工知能(AI)はいま、開発と本格運用が同時進行する新しい段階へと向かいつつある。広範囲の実用化に際し、どんな課題が待ち受けるのか。日本の競争力を高めることはできるのか。新たな視点の構築や戦略の立案が必要になっている。
思いがけない出来事は、深く、強く、私たちの心を揺さぶるインパクトがある。ここ数年、人工知能に関連したニュースは、こうした「想定外」のものが群を抜いて多かった。
グーグル傘下の英ディープマインド社が開発した囲碁AI「アルファ碁」は「あと10年はかかる」という大方の予想を覆し、世界のトップ棋士を相次いで破ってみせた。2020年代の実用化をめざす自動運転では、運転席に誰も座らない形での公道試験が始まっている。ネット上の最新の機械翻訳サービスを活用すれば、想像以上にこなれた翻訳を読んだり聞いたりできる。
人により、どのニュースに最も驚いたかは、異なるかもしれない。しかし、いずれも5年前に専門家に質問したら「まだ先の話だ」「そう簡単ではない」といった答えが返ってきただろう。では、なぜ、これほど急ピッチでの進歩が短期間のうちに達成できたのか。まずは人工知能の歴史をひもときながら、今回のブームへの流れをみていこう。
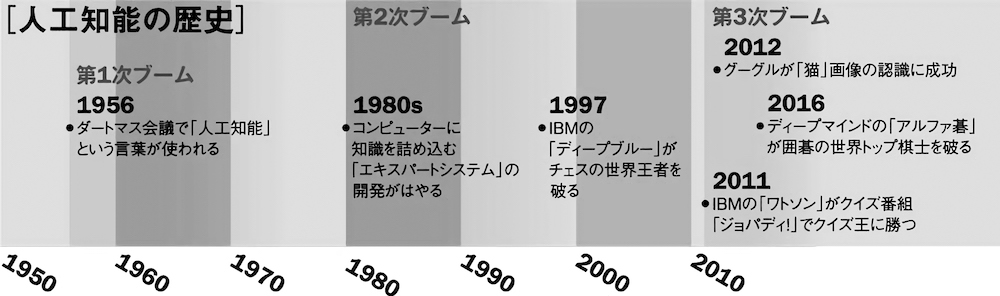 人工知能の歴史
人工知能の歴史人工知能という言葉には、厳密な定義があるわけではない。機械に人間と同じような知能を持たせようという試みの総称であり、その過程で生まれた技術は様々な機器やソフトに使われている。ワープロ専用機やワープロソフトも、自然言語処理という分野の人工知能研究のなかから生まれたものだ。
もともと「考える機械」という概念は、第二次世界大戦前後のコンピューター研究を背景に、1947年、英数学者アラン・チューリングが提唱した。56年には、米研究者ジョン・マッカーシー、マービン・ミンスキーらが人工知能(Artificial Intelligence、AI)という言葉を初めて使ったダートマス会議を開催。多くの研究者の夢になった。
実現に向けた考え方には、大きく二つの流派がある。論理やルールに重きをおいてプログラムを組む考え方と、脳の神経細胞(ニューロン)を模したAIをつくり自らに学習させようという考え方だ。この二つの流派がそれぞれ浮き沈みを繰り返しながら、現在のブームをふくめ、三つの大きなブームを形作ってきた。
まず最初のブームはダートマス会議が開かれた56年から60年代にかけてをさす。人工知能という言葉が使われだし、誕生間もないコンピューターで簡単な推論や経路の探索を試みる、いわば基礎研究の時代だった。そのなかで二つの流派が生まれたが、現実的な問題に対応するまでには至らなかった。
第二次ブームは1970年代後半から90年代初頭まで続いた。論理とルールに専門家の「知識」を加えた「エキスパートシステム」を作れば、現実的な問題にも対処できるという発想で、日本ではシステム実現のため、第五世代コンピューターの開発プロジェクトが立ち上がった。しかし、人間は、人の見分け方、自転車の乗り方、不良品を見分けるコツなど、無意識にしていること、会得したノウハウなどを、すべて言葉で表現することができない。こうした「暗黙知」を教え込めず、プロジェクトは結局、大きな成果を示せないまま、終了した。
これに対し現在の第三次ブームを支えているのは、深層学習(ディープラーニング)と呼ばれるニューラルネットワーク型の人工知能だ。第一次ブームの際に生まれたニューラルネットのアイデアを進化させ、大量のデータを読み込むことで、AI自らが学習し、データの特徴や傾向値を導きだすようにした。
2012年6月、まずグーグルが1000万枚の画像で学習した人工知能の成果を発表、機械がネコを認識したと話題になった。同じ年、画像認識の国際コンテストでも深層学習型の人工知能が上位を独占、その実力が確認された。
それから6年。技術進歩は専門家の予想をはるかにこえ、すでに画像認識能力は人間を大きく上回るレベルにある。音声認識や言語処理の能力も格段に向上し、似た言語同士であれば、自動翻訳も人とほぼ同じレベルになった。画像をみて、その内容を文章や音声で説明することも、その逆に文章の内容にそった画像を生成することもできる。たとえば「空飛ぶ自動車」と書き込めば、青空に浮かぶ自動車の画像があらわれる。
 グーグルのAI開発部門リーダーのジェフ・ディーン氏
グーグルのAI開発部門リーダーのジェフ・ディーン氏もともと深層学習で使われているアイデアは1980年代半ばから90年代にかけ、すでに提案されていたものだった。しかし当時はまだ大量のデータを扱う能力を持ちえなかった。
一方、コンピューターの世界では1年半から2年でその能力が倍になるという経験則がある。「ムーアの法則」と呼ばれ、仮に1年半で2倍になるとすると、10年で100倍、20年で1万倍の能力増となる。2000年代に入りインターネット上の情報量も急速に増加した。計算力とビッグデータ双方の急拡大で、ニューラルネット型AIは使える道具になったわけだ。
ただ、どんな大きな変化も、頻繁に見聞きし、体験するようになれば、驚きの度合いは徐々に小さくなっていく。
今年5月、グーグルは開発者向け会議で、AIがレストランや美容院に電話をかけ予約をとる様子を紹介した。相手にAIと気づかせない自然なやりとりは、すごいと感じる一方で、自宅のスマートスピーカーに語りかけ、ニュースや天気予報を聞いたり、音楽を流したり、様々な機器を動かしたりできるいま、かつてのようなインパクトがあるわけではない。
巨石が池に投げ込まれて生じた大きなうねりも周囲に広がっていくうちに徐々に小さくなっていく。AIをめぐるブームも、中心部で起きた最初の巨大なうねりが周囲に広がり様々な場所でごく当たり前のように実用システムとして組み込まれる局面にきている。
では、実際の利用に際しどんな注意が必要だろうか。ひとつはブラックボックス問題。もうひとつはデータバイアスの問題だ。
人工知能がなぜ、この答えを出したのか。その道筋が外からみえない「ブラックボックス」問題はニューラルネット型AIが解決すべき最初の課題だ。実はこの問題は、第二次ブームの際、人の知識を人工知能に教え込むのに失敗したことと裏表の関係にある。エキスパートシステムでは、専門家が自らの知識すべてを言語化できなかった。第三次ブームでは、こんどはAI側が、見つけた答えを言語化して人間に伝えられない。人間の専売特許と思っていた「暗黙知」を、AIが持つようになったのだ。
わかりやすい事例はディープマインド社のアルファ碁と韓国のトップ棋士、イ・セドルとの対局だろう。対局の途中、イ・セドルはアルファ碁の打った手に何度か怪訝な表情を浮かべた。手の意図が読み取れなかったのだ。そして対局が進むと、それが妙手だったことがわかってくる。こんな局面が何回かあった。その後、ディープマインド社はバージョンアップしたアルファ碁同士が対局した棋譜を公開したが、そこにはプロの棋士にも理解できない手がいくつもあった。
性能がよくなればなるほどニューラルネット型AIは、答えの理由を自ら説明するのが難しくなる。ごく普通の画像認識なら、結果が良好ならとくに問題はない。しかし、医療分野での画像診断などではAIによる予測や分析と同時に、なぜその診断となったのか、その理由を説明するための技術が必要になる。今後、実用化される自動運転車などでも同様だ。
もうひとつの課題「データバイアス」は人工知能が学習する際に必要な大量のデータに偏りはないかという問題だ。
実はビッグデータには様々なバイアスがついて回る。たとえば職業に関するバイアス。医師は男性、看護師は女性と結びつくことが多く、古いデータほど、その傾向は強く出る。このまま職業適性診断などに使えば、医師は男性向き、看護師は女性向きという偏りが生じてしまう。事前にデータからバイアスを取り除くか、でてきた分析に補正をかけて修正するか、いずれかの作業が必要になる。
人種差別がセンシティブな問題となる米国では、犯罪予測モデルのデータに「郵便番号」を入れていいかが議論になったこともある。米国では、住むエリアが人種ごとに分かれることが少なくない。学習用の犯罪データのひとつに住所を使うと、かつての人種差別の偏見が将来予測に持ち込まれるのではないか。そんな懸念が広がったためだった。
もともと社会の価値観や公正の概念は時代によって変化する。かつての常識が偏見や誤りとなることが少なくない。過去に引きずられないためには、データにどんなバイアスがひそんでいるか、定期的に再点検することが欠かせない。
ブラックボックスとデータバイアスが重なると人工知能がはじきだすのは反証の機会のないゆがんだ分析結果となる。
とくにネット上を流れる情報には、悪意の有無を別にしても、事実とは異なるものが少なくない。トランプ米大統領を選出した16年の大統領選挙の際、両陣営とは何の関係もない東欧・マケドニアの青年たちが、サイトのアクセス数稼ぎのために、ヒラリー・クリントン候補にまつわる偽ニュースを発信し続けた例もある。利用者が不当な不利益を被らないようにするルールが必要になるだろう。
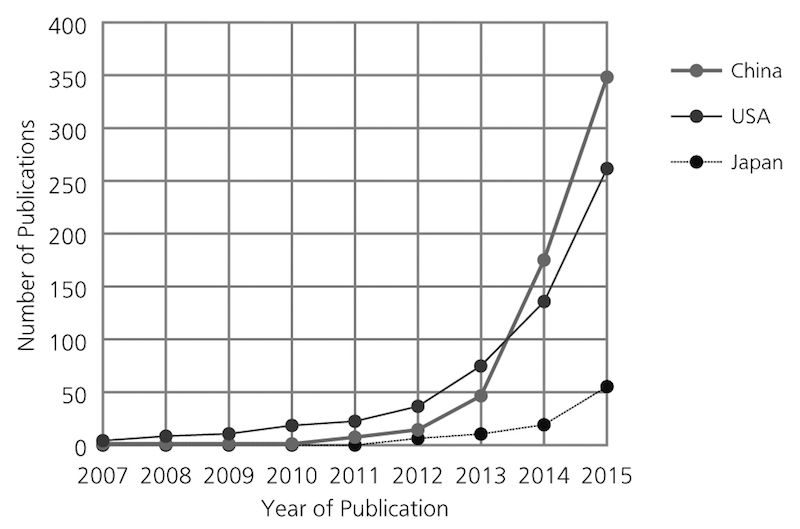 深層学習に言及した科学雑誌の記事・論文数
深層学習に言及した科学雑誌の記事・論文数産業界も長期の低迷から脱しきれない。ほとんどの情報流通がインターネットへとシフトするなか、ネットワークサービスを提供する世界的企業は、ほぼすべて米国企業の独占状態となった。
なかでも人工知能を自ら率先して活用してきたのが検索大手のグーグル(Google)、ネット通販のアマゾン(Amazon)、ソーシャルメディアのフェイスブック(facebook)、PC・スマホメーカーのアップル(Apple)の4社。それぞれの頭文字をつなげ「GAFA(ガーファ)」と呼ばれている。これにマイクロソフトやIBMを加えると主要プレーヤーがほぼでそろう。
GAFAの4社は、それぞれほかの3社とバッティングしない専門領域と収益構造をもつことで、安定した経営環境を整え、巨大なネットワークシステムを自社のサービスのために構築している。これが人工知能技術を自社のために開発するインセンティブになる。
事業の中身は違ってもシステムはある意味似ていて、それぞれ相手のビジネス分野にも乗り出せる潜在的なライバル関係にある。たとえば音楽配信は、アマゾン、グーグル、アップルが行っており、その延長線上で、アマゾンがスマートスピーカーを売り出すと、グーグル、アップルも追随。リビングルームの「覇権」を争っている。
米国の4強と合わせ鏡のように、同じ構造で競い合うのが中国のIT企業だ。グーグルやフェイスブックが、中国ではアクセスが制限され、大規模な事業を展開できないなか、検索大手のバイドゥ(Baidu)、ネット通販のアリババ(Alibaba)、ソーシャルメディアのテンセント(Tencent)の「BAT」が、人口13億人の巨大な市場で、圧倒的なシェアを得ている。これにスマートフォンのファーウェイ(HUAWEI)を加えた「BATH」が中国の4強となる。
国内市場での安定収益と、
有料会員の方はログインページに進み、デジタル版のIDとパスワードでログインしてください
一部の記事は有料会員以外の方もログインせずに全文を閲覧できます。
ご利用方法はアーカイブトップでご確認ください
朝日新聞社の言論サイトRe:Ron(リロン)もご覧ください