- 文字サイズ
- 小
- 中
- 大
統計学を使えば最小の費用で最大の効果が得られる調査方法がわかる
2019年02月26日
 統計不正問題を取り上げた衆院予算委員会で、根本匠厚労相(右)の答弁を制止する立憲民主党の長妻昭代表代行(左)=2019年2月4日、松本俊撮影
統計不正問題を取り上げた衆院予算委員会で、根本匠厚労相(右)の答弁を制止する立憲民主党の長妻昭代表代行(左)=2019年2月4日、松本俊撮影この調査は、500人以上の事業所は全数調査、499人以下の事業所は一部を抽出して調査すると法律で定められている。ところが、東京都は500人以上の事業所も約3分の1を抽出して調査していた、というのが大きな問題点である。それにとどまらず、統計処理にもミスがあった。その結果、雇用保険や労災保険の給付金を算定するときの基礎となる「決まって支給する給与」(いわゆる平均給与)が本来より少なく公表されていた。
厚労省の発表資料に載っている表をグラフにしたのが以下である。
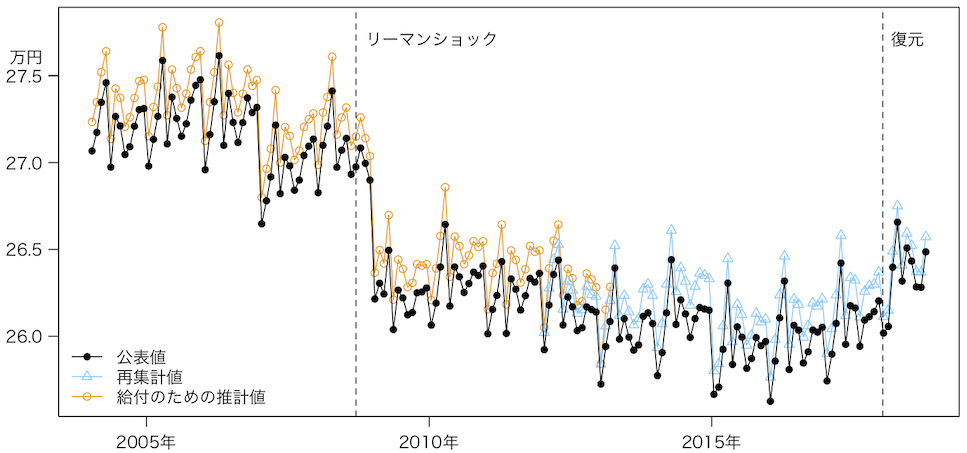 「きまって支給する給与」の推移
「きまって支給する給与」の推移今回明らかになったのは、(1)東京都が500人以上規模の事業所について全数でなく抽出調査をしていた(2)しかも2017年までは「復元」(詳しくは以下で説明する)をしておらず、2018年から「復元」を始めた(3)もともと抽出調査だった30人以上499人以下の事業所についても、2009年以降、東京都の一部で正しい「復元」が行われていなかった、という不正及びミスである。
計算をやり直したところ、上のグラフの青(△)のようになった。また、元データが残っていない古い時代については、より簡単な計算で補正したところ、オレンジ色(○)のようになった。
厚労省はどこを間違ったのか。また、「復元」とは何か。
話を簡単にするため、日本には従業員100人の小事業所と、従業員1000人の大事業所しかないと仮定しよう。小事業所は10万社あり、大事業所の方は1万社と仮定する。
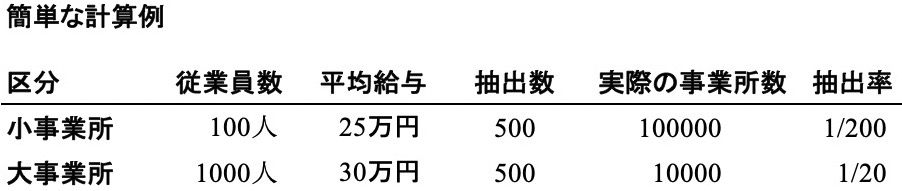
正しい計算は、実際の事業所数を使って、次のようにしなければならない。全国の小事業所が払った給与の総額は100×25万×100000=2.5兆円、大事業所が払った給与の総額は1000×30万×10000=3兆円、合わせて5.5兆円である。これを全国の従業員数100×100000+1000×10000=2000万人で割れば、1人あたりの給与は27.5万円となる。これが正しい。
要は、抽出した数ではなく、実際の数(全体)を使わなければならないのである。
この「間違った計算を正しくする処理」を、厚労省では「復元」と呼んでいるようであるが、特別な処理ではなく、ごく当たり前の計算である。
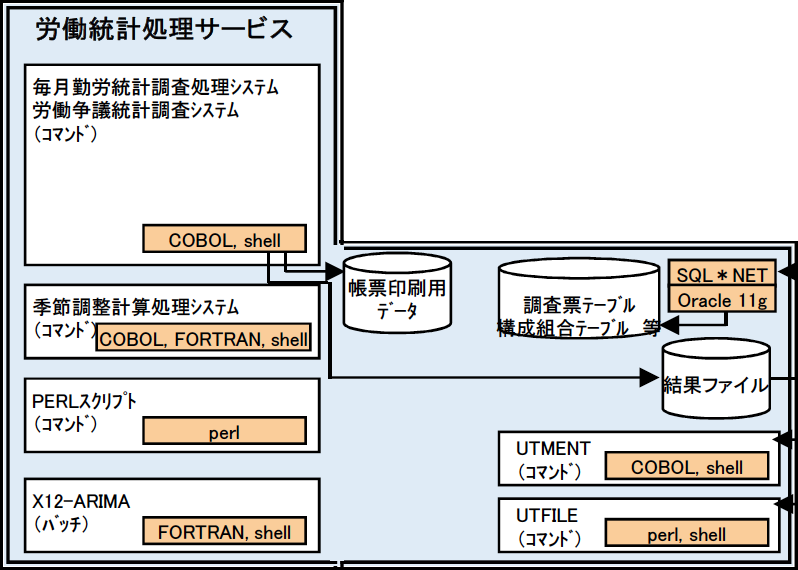 厚労省「労働統計処理サービス」ソフトウェア構成図
厚労省「労働統計処理サービス」ソフトウェア構成図厚労省は、「500人以上規模の事業所」について全数調査のつもりで作った計算プログラムに、抽出率1/3のデータを入力したため、間違った平均給与が出力されたと説明する。毎月勤労統計調査を巡る不適切な取扱いに係る事実関係とその評価等に関する報告書によれば、計算プログラムはCOBOL(コボル)という古い言語で書かれており、簡単に修正できなかったとのことである。実際、2018年3月の統計処理システム更改及び運用・保守一式調達仕様書別紙13(一部を図に示す)によれば、労働統計関係のシステムはCOBOL、FORTRAN(フォートラン)といった往年の言語とOracle(オラクル)社のデータベースで構成されており、私でも触りたくない。
ところで、ふつうは同じ小事業所でもAでは27万円、Bでは23万円というように、ばらつきがある。ばらつきがある中で一部を抽出して平均値をとった場合、誤差が残る。どれだけ抽出すればどれだけの誤差があるのか。また、誤差を最小にするためには、大小の事業所をどのような比率で抽出すればよいのか。こういうことを明らかにするのが統計学である。
以下では、
有料会員の方はログインページに進み、デジタル版のIDとパスワードでログインしてください
一部の記事は有料会員以外の方もログインせずに全文を閲覧できます。
ご利用方法はアーカイブトップでご確認ください
朝日新聞社の言論サイトRe:Ron(リロン)もご覧ください